At CLIN2023, the 33rd Meeting of Computational Linguistics in The Netherlands, Carsten Schnober presented a paper in which we consider the quality of lemmatization and part-of-speech (POS) tagging results from a number of standard parsers often used in computational research (and natural language processing tasks in general). We came to this comparison because, when inspecting the first results of parsing our corpus of 20,000 novels, some surprising lemmatization errors stood out. For instance “woonkeuken” (Dutch, literally “living-kitchen”) and its plural “woonkeukens” were lemmatized by the same parser respectively as “woonkeuken” (which is the correct lemma in Dutch) and “woonkeuok” (which is not a lemma for any word in any language we are aware of). For the research on themes and topics used in fiction, correct lemmatization is important.

One may wonder why, if we are interested in the topics that are found in novels, we would be interested in lemma information. What does lemmatization have to do with an analysis of topics? In natural language texts, different variants of a basic word are found, such as the verb ‘fly’, ‘flies’, ‘flew’ and ‘flying’, which all have the same lemma ‘to fly’. If we want to know which texts use many of the same words, we often consider different word forms to be irrelevant. If two texts are about flying, we don’t care that one uses ‘flew’ and the other ‘flies’. If we ask an algorithm to do the comparison for us, we need to tell it that ‘flew’ and ‘flies’ are different word forms of the same underlying verb ‘to fly’.
Our corpus contains almost 20,000 novels, and over 1.5 billion words. That is too much to derive all the lemmas by hand without getting extremely bored (and old), so we want to use syntactic parsers to give us the lemma of each of those 1.5 billion words. For Dutch, there are numerous software packages that can do syntactic parsing, so we need to choose which one to use. We have two criteria: speed and accuracy. Speed is important, because 1.5 billion words is a lot. The Alpino (https://github.com/rug-compling/Alpino) parser is known as one of the most accurate parsers for Dutch. It analyzes sentences not only on lemma information, but also on part-of-speech, tense, aspect, and many other linguistic aspects. It considers many alternative interpretations to choose the best one. As a consequence, it processes a dozen words per second (this is a ballpark figure, and in reality of course depends on the computational resources available. What matters here is the order of magnitude). A quick calculation tells us that it would take several years to complete the analysis of all 20,000 novels. Spacy (https://spacy.io/) on the other hand, is built for speed and processes around 12,000 words per second (again, only a ballpark figure). It would do the job in a day and a half. But we found that it is less accurate.
That a parser would sometimes make errors is not necessarily a problem. Assuming the errors are few and isolated, they will not affect overall results too much. But it does become a problem when different variants of the same word result in different lemmas. For instance, when the lemmas are used to assign certain categories of topics to certain novels. If ‘woonkeukens’ is used in one book and ‘woonkeuken’ is used in another, and the parser derives different lemmas from them, the topic analysis will not find a connection between these books based on these variants. If our lemmas turn out to be unreliable to a certain extent, then also the topics they describe will be unreliable. And if our topics are unreliable, how do we know what topics are most associated with positive or negative reading experiences that we find in online book reviews? So, one can see that, when an operation as basic as parsing has gone askew, it results in a feeble foundation for analyzing aspects of fiction that rely on that basic operation. Thus it is important to know how many and what type of errors different parsers make, especially in our case in lemmatization.
There are standard evaluation test sets that are used to measure the accuracy of parsers, but these test sets contain sentences taken from news articles, which are fairly uniform. Literary text is highly diverse and includes for instance dialogues, indirect speech, elaborate descriptions, and so forth. It is not clear what the best parser is for literary texts.
For our project we wanted to establish if the parsing we use is reliable enough. For this we created six random samples of 100 sentences from the novel corpus and we had these parsed by five different parsers: Alpino, Frog (http://languagemachines.github.io/frog/), SpaCy, Stanza (https://stanfordnlp.github.io/stanza/), and Trankit (https://trankit.readthedocs.io/en/latest/). Subsequently we had six human annotators check the results for tokenization, POS tagging, and lemmatization. In our case it turned out that all parsers make errors in every task. Lemmatization error rate varies between 0.5 to 3.5 percent of tokens, while POS tagging error rate varies between roughly 2.5 and 4 percent. We also saw that parsers get verbs and nouns wrong disproportionate to the use of such words. That is: while verbs and nouns are generally used less than other words, they are being misclassified by parsers relatively more often.
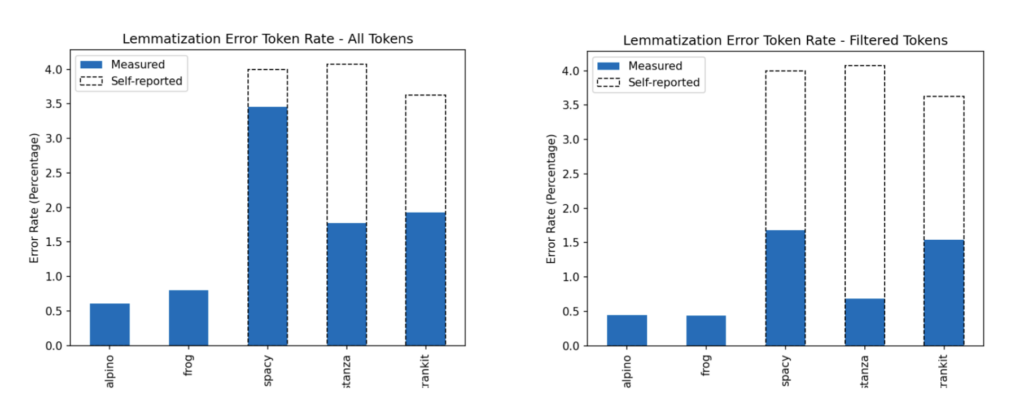
The manual evaluation we did thus showed that parsers do make errors. Obviously that is not big news, we know that parsers are not perfect. But does the amount and rate of errors made in literary texts negatively impact our power of analysis? For topic analysis, we want to focus on content words and ignore the many function words (determiners like ‘the’, ‘a’ and prepositions like ‘in’, ‘on’, ‘at’). Moreover, many content words are so common that they either don’t tell us much about the topic of a book or they occur in most books (words like ‘way’, ‘door’ or ‘say’), so they can’t help us identify differences between books. We choose to focus on words that are nouns, verbs, adjectives and adverbs, and only those that occur in no more than 10% of all books (otherwise they are too common and don’t differentiate between books) and at least 1% of all books (otherwise they are too specific). This removes 93% of all words, and thus leaves us with only 7% of the original texts. Within this subset, the error rate could be much higher, as we expect that more common words are more likely to occur in the data that was used to train the parsers, and many of the words we focus on are less likely to occur in the training data. Surprisingly, we find that among the words we focus on, the error rate is actually lower than when we include all words, i.e. between 0.4 and 1.7 percent.
After interpreting the numbers, we believe we can err on the side of safety. It turns out first of all that human annotators report less POS tagging and lemmatization error rates than are self-reported in parser documentation. In some cases a lemma may be wrong according to a linguistic golden standard while humans actually cannot really agree what the correct lemma is. This means that some tokens can be lemmatized in multiple ways without there being necessarily only one right or perfect way. If such lemmas end up in more than one topic, that is not an error per se. Secondly, base error rate as established by that manual evaluation is low in any event. We conclude from these facts that we can safely opt for the parser, from among the five tested, that represents the sweet spot between speed and accuracy of parsing.
The take away for us is that going the extra mile to evaluate parsers for your specific task is a sensible methodological precaution to take. If correct lemmatization is pivotal to your task or research question you need to be able to tell how well your chosen parser behaves. In our paper we detailed how even annotating and evaluating a mere 100 sentences as a test corpus will reveal which parser may offer the best performance for your specific task. This gives you an additional measure of reliability to the robustness of your research, and seems to us a good practice above putting your trust in standard evaluation sets alone.